
Word2vec Tensorflow
Deep Learning (from Tensorflow Tutorial)
Assignment 5
The goal of this assignment is to train a Word2Vec skip-gram model over Text8 data.
# These are all the modules we'll be using later. Make sure you can import them
# before proceeding further.
%matplotlib inline
from __future__ import print_function
import collections
import math
import numpy as np
import os
import random
import tensorflow as tf
import zipfile
from matplotlib import pylab
from six.moves import range
from six.moves.urllib.request import urlretrieve
from sklearn.manifold import TSNE
Download the data from the source website if necessary.
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
"""Download a file if not present, and make sure it's the right size."""
if not os.path.exists(filename):
filename, _ = urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified %s' % filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
Found and verified text8.zip
Read the data into a string.
def read_data(filename):
"""Extract the first file enclosed in a zip file as a list of words"""
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
words = read_data(filename)
print('Data size %d' % len(words))
Data size 17005207
Build the dictionary and replace rare words with UNK token.
vocabulary_size = 50000
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0 # dictionary['UNK']
unk_count = unk_count + 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words)
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10])
del words # Hint to reduce memory.
Most common words (+UNK) [['UNK', 418391], ('the', 1061396), ('of', 593677), ('and', 416629), ('one', 411764)]
Sample data [5234, 3084, 12, 6, 195, 2, 3136, 46, 59, 156]
Function to generate a training batch for the skip-gram model.
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ]
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window # target label at the center of the buffer
targets_to_avoid = [ skip_window ]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
print('data:', [reverse_dictionary[di] for di in data[:8]])
for num_skips, skip_window in [(2, 1), (4, 2)]:
data_index = 0
batch, labels = generate_batch(batch_size=8, num_skips=num_skips, skip_window=skip_window)
print('\nwith num_skips = %d and skip_window = %d:' % (num_skips, skip_window))
print(' batch:', [reverse_dictionary[bi] for bi in batch])
print(' labels:', [reverse_dictionary[li] for li in labels.reshape(8)])
data: ['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first']
with num_skips = 2 and skip_window = 1:
batch: ['originated', 'originated', 'as', 'as', 'a', 'a', 'term', 'term']
labels: ['as', 'anarchism', 'a', 'originated', 'as', 'term', 'of', 'a']
with num_skips = 4 and skip_window = 2:
batch: ['as', 'as', 'as', 'as', 'a', 'a', 'a', 'a']
labels: ['anarchism', 'term', 'originated', 'a', 'term', 'originated', 'of', 'as']
Train a skip-gram model.
batch_size = 128
embedding_size = 128 # Dimension of the embedding vector.
skip_window = 1 # How many words to consider left and right.
num_skips = 2 # How many times to reuse an input to generate a label.
# We pick a random validation set to sample nearest neighbors. here we limit the
# validation samples to the words that have a low numeric ID, which by
# construction are also the most frequent.
valid_size = 16 # Random set of words to evaluate similarity on.
valid_window = 100 # Only pick dev samples in the head of the distribution.
valid_examples = np.array(random.sample(range(valid_window), valid_size))
num_sampled = 64 # Number of negative examples to sample.
graph = tf.Graph()
with graph.as_default(), tf.device('/cpu:0'):
# Input data.
train_dataset = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Variables.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
softmax_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
softmax_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Model.
# Look up embeddings for inputs.
embed = tf.nn.embedding_lookup(embeddings, train_dataset)
# Compute the softmax loss, using a sample of the negative labels each time.
loss = tf.reduce_mean(
tf.nn.sampled_softmax_loss(weights=softmax_weights, biases=softmax_biases, inputs=embed,
labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size))
# Optimizer.
# Note: The optimizer will optimize the softmax_weights AND the embeddings.
# This is because the embeddings are defined as a variable quantity and the
# optimizer's `minimize` method will by default modify all variable quantities
# that contribute to the tensor it is passed.
# See docs on `tf.train.Optimizer.minimize()` for more details.
optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss)
# Compute the similarity between minibatch examples and all embeddings.
# We use the cosine distance:
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings))
num_steps = 100001
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print('Initialized')
average_loss = 0
for step in range(num_steps):
batch_data, batch_labels = generate_batch(
batch_size, num_skips, skip_window)
feed_dict = {train_dataset : batch_data, train_labels : batch_labels}
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
if step % 2000 == 0:
if step > 0:
average_loss = average_loss / 2000
# The average loss is an estimate of the loss over the last 2000 batches.
print('Average loss at step %d: %f' % (step, average_loss))
average_loss = 0
# note that this is expensive (~20% slowdown if computed every 500 steps)
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log = 'Nearest to %s:' % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log = '%s %s,' % (log, close_word)
print(log)
final_embeddings = normalized_embeddings.eval()
Initialized
Average loss at step 0: 8.001144
Nearest to from: christians, gunfire, forage, kiesinger, prasad, departments, reels, includes,
Nearest to system: bermuda, quincey, horseback, stephane, unite, scaffold, agriculture, caldera,
Nearest to was: mona, trafficking, decoders, humoral, favors, unbridled, cellulose, tca,
Nearest to first: diophantus, nicolai, niece, seventies, blueprint, chromatic, parrot, donkeys,
Nearest to so: longinus, gesserit, atom, apok, adverbial, oxidizes, pendant, culprits,
Nearest to it: aquilonia, tuesday, boehm, winning, malicious, eduke, dodecanese, bid,
Nearest to united: rebuilding, pancreas, perrault, mongolia, calcium, devised, icbms, activision,
Nearest to there: statistician, khosrau, labours, prostaglandin, addams, regiment, injecting, antiparticles,
Nearest to his: chittagong, mariani, hypothermia, governance, whispers, mauss, sanderson, qdos,
Nearest to no: ocogs, offender, dial, utah, reconstructed, hibernation, formalism, undergoes,
Nearest to that: contemplate, cheat, ailey, costumed, constellations, despised, films, dyed,
Nearest to into: sark, bung, debrecen, dioscorus, invertebrates, reflects, creep, clitoris,
Nearest to new: bureaucracies, themselves, performances, doctrine, apostles, nadezhda, drosophila, crusaders,
Nearest to such: nonsignatory, ridge, chimes, waterbury, xxxiv, landslide, webmineral, lilies,
Nearest to of: psych, martinez, jennifer, wetter, antennae, reportedly, guerra, cages,
Nearest to american: easterners, highs, declares, inlay, restriction, nero, voltage, abilene,
Average loss at step 2000: 4.370419
Average loss at step 4000: 3.872616
Average loss at step 6000: 3.793469
Average loss at step 8000: 3.690683
Average loss at step 10000: 3.617514
Nearest to from: in, of, by, includes, into, at, on, merriam,
Nearest to system: bermuda, caldera, cataclysm, lokasenna, scaffold, quincey, language, voight,
Nearest to was: is, were, had, has, by, geist, be, stratigraphic,
Nearest to first: diophantus, meade, honshu, niece, hardware, trintignant, nicolai, females,
Nearest to so: longinus, leave, but, gesserit, specialized, oxidizes, say, practiced,
Nearest to it: he, this, there, they, not, that, vashem, boehm,
Nearest to united: rebuilding, icbms, second, totalling, savile, across, bremer, activision,
Nearest to there: it, no, they, khosrau, vasco, statistician, authored, gec,
Nearest to his: their, her, s, the, its, proprietary, whispers, proactive,
Nearest to no: ocogs, offender, dial, there, about, wildstorm, sedan, constituency,
Nearest to that: which, it, what, this, onager, they, tanker, swordsmiths,
Nearest to into: with, dioscorus, mycenaean, to, from, kinases, recorder, photographic,
Nearest to new: vlaanderen, bureaucracies, rely, nadezhda, beverage, easy, withdrawing, drosophila,
Nearest to such: sideband, well, samaritan, licks, ridge, fes, webmineral, vega,
Nearest to of: in, from, for, and, fudge, int, at, perk,
Nearest to american: voltage, murderous, declares, multiplies, devastates, kanembu, kahn, easterners,
Average loss at step 12000: 3.608412
Average loss at step 14000: 3.575740
Average loss at step 16000: 3.414840
Average loss at step 18000: 3.458065
Average loss at step 20000: 3.542493
Nearest to from: into, at, through, in, includes, sectarian, by, academie,
Nearest to system: bermuda, language, animating, awards, shimon, ceo, cataclysm, lokasenna,
Nearest to was: is, has, were, had, are, be, gorillaz, became,
Nearest to first: meade, diophantus, females, earliest, hardware, honshu, last, niece,
Nearest to so: longinus, leave, analgesic, gesserit, anyone, specialized, say, harry,
Nearest to it: he, there, this, she, they, which, also, not,
Nearest to united: rebuilding, across, savile, atlas, totalling, bremer, tess, icbms,
Nearest to there: it, they, he, badgers, still, often, who, no,
Nearest to his: their, her, its, the, proprietary, ceased, elegantly, mandates,
Nearest to no: ocogs, a, offender, there, wildstorm, dial, constituency, prairies,
Nearest to that: which, this, but, what, when, also, it, onager,
Nearest to into: from, kinases, mycenaean, with, dioscorus, picturesque, clitoris, russ,
Nearest to new: vlaanderen, beverage, bureaucracies, rely, downloads, easy, largo, sheppard,
Nearest to such: well, sideband, samaritan, known, other, ridge, licks, these,
Nearest to of: for, in, despite, int, kondratiev, same, bebop, sheppard,
Nearest to american: british, kanembu, seasonally, clarinetists, dartmouth, genomes, elevated, french,
Average loss at step 22000: 3.500895
Average loss at step 24000: 3.490118
Average loss at step 26000: 3.482253
Average loss at step 28000: 3.482119
Average loss at step 30000: 3.505217
Nearest to from: into, under, in, by, through, after, on, puzo,
Nearest to system: animating, bermuda, amerindian, awards, lokasenna, ceo, chernobyl, managing,
Nearest to was: is, were, had, has, became, been, chadian, when,
Nearest to first: last, second, females, mistook, earliest, throughout, signatures, favoured,
Nearest to so: longinus, analgesic, leave, say, specialized, perilous, gesserit, decius,
Nearest to it: he, there, this, they, she, also, which, often,
Nearest to united: rebuilding, across, atlas, savile, philistines, totalling, forseti, icbms,
Nearest to there: they, it, he, still, often, badgers, no, usually,
Nearest to his: their, her, its, the, s, my, loanwords, christie,
Nearest to no: ocogs, a, there, any, wildstorm, dial, mcintyre, offender,
Nearest to that: which, what, however, this, but, about, unreadable, when,
Nearest to into: from, dioscorus, kinases, lukewarm, upon, over, picturesque, mycenaean,
Nearest to new: sheppard, rely, beverage, vlaanderen, bureaucracies, policy, member, previous,
Nearest to such: well, these, licks, sideband, ridge, samaritan, known, including,
Nearest to of: in, and, for, hurriedly, from, forgetting, prover, marker,
Nearest to american: british, english, and, croatia, african, french, overwrite, german,
Average loss at step 32000: 3.501175
Average loss at step 34000: 3.493462
Average loss at step 36000: 3.451154
Average loss at step 38000: 3.303560
Average loss at step 40000: 3.425723
Nearest to from: into, through, under, of, for, off, in, on,
Nearest to system: bermuda, systems, awards, lokasenna, animating, amerindian, endowment, utterly,
Nearest to was: is, were, had, has, became, been, todd, chadian,
Nearest to first: last, second, signatures, editors, entire, previous, females, fourth,
Nearest to so: longinus, analgesic, perilous, anyone, weaker, interplanetary, concluded, say,
Nearest to it: he, she, there, this, they, still, also, not,
Nearest to united: rebuilding, across, atlas, philistines, savile, icbms, totalling, tess,
Nearest to there: it, they, he, still, often, now, usually, badgers,
Nearest to his: their, her, its, my, s, the, proprietary, loanwords,
Nearest to no: ocogs, any, there, or, wildstorm, a, only, than,
Nearest to that: which, this, what, however, who, when, because, it,
Nearest to into: from, dioscorus, through, clitoris, debrecen, lukewarm, russ, kinases,
Nearest to new: member, vlaanderen, rely, bureaucracies, saltwater, ponce, previous, wake,
Nearest to such: well, these, including, licks, known, samaritan, ridge, sideband,
Nearest to of: in, for, including, bebop, from, containing, same, celera,
Nearest to american: british, english, prickly, african, croatia, french, russian, german,
Average loss at step 42000: 3.436469
Average loss at step 44000: 3.453519
Average loss at step 46000: 3.454578
Average loss at step 48000: 3.348724
Average loss at step 50000: 3.384169
Nearest to from: into, in, through, sectarian, casing, under, around, meteorites,
Nearest to system: systems, animating, bermuda, chernobyl, lokasenna, amerindian, awards, thorny,
Nearest to was: is, has, were, became, had, be, been, by,
Nearest to first: second, last, next, only, fourth, asu, females, throughout,
Nearest to so: longinus, owsley, flatten, analgesic, concluded, perilous, say, impartiality,
Nearest to it: he, there, she, this, they, still, quickly, numeration,
Nearest to united: rebuilding, across, atlas, philistines, savile, icbms, temple, wikimedia,
Nearest to there: they, it, he, often, still, we, now, who,
Nearest to his: her, their, its, my, your, our, the, fins,
Nearest to no: ocogs, any, a, wildstorm, seminole, gomez, lucien, compromised,
Nearest to that: which, however, what, this, where, overly, but, liqueur,
Nearest to into: from, through, dioscorus, back, russ, lukewarm, over, kinases,
Nearest to new: vlaanderen, policy, previous, member, ponce, sheppard, rely, abomination,
Nearest to such: well, these, known, licks, samaritan, including, certain, ridge,
Nearest to of: in, hobbyists, including, and, for, perp, despite, int,
Nearest to american: african, english, british, european, french, prickly, russian, kanembu,
Average loss at step 52000: 3.437811
Average loss at step 54000: 3.429439
Average loss at step 56000: 3.441146
Average loss at step 58000: 3.396283
Average loss at step 60000: 3.399652
Nearest to from: into, through, affiliation, under, casing, dreaded, in, ventricle,
Nearest to system: systems, animating, bermuda, endowment, methods, lokasenna, thorny, chernobyl,
Nearest to was: is, had, has, were, became, be, been, when,
Nearest to first: last, second, next, best, same, fourth, previous, ensuing,
Nearest to so: concluded, analgesic, too, weaker, then, perilous, if, extremely,
Nearest to it: he, there, she, this, numeration, they, that, which,
Nearest to united: rebuilding, philistines, across, atlas, savile, totalling, icbms, wikimedia,
Nearest to there: they, it, he, she, still, often, we, this,
Nearest to his: her, their, its, my, your, the, fins, our,
Nearest to no: ocogs, any, shed, seminole, concerned, gomez, laval, a,
Nearest to that: which, this, what, however, it, there, often, where,
Nearest to into: through, from, dioscorus, over, in, lukewarm, unauthorized, around,
Nearest to new: ponce, previous, member, policy, rely, vlaanderen, actresses, milford,
Nearest to such: well, these, known, licks, many, including, samaritan, sedentary,
Nearest to of: for, in, although, same, including, forgetting, millie, gunpoint,
Nearest to american: african, british, english, european, french, electronic, russian, trevor,
Average loss at step 62000: 3.240701
Average loss at step 64000: 3.256361
Average loss at step 66000: 3.400887
Average loss at step 68000: 3.396135
Average loss at step 70000: 3.363147
Nearest to from: through, into, in, between, within, sectarian, during, meteorites,
Nearest to system: systems, animating, donatello, endowment, methods, thorny, jacinto, awards,
Nearest to was: is, has, had, were, became, been, does, todd,
Nearest to first: second, last, next, best, same, fourth, entire, previous,
Nearest to so: then, thus, perilous, analgesic, concluded, too, if, sometimes,
Nearest to it: he, she, there, this, they, still, purr, we,
Nearest to united: rebuilding, atlas, philistines, across, icbms, savile, wikimedia, totalling,
Nearest to there: they, it, still, he, we, usually, currently, often,
Nearest to his: her, their, its, my, your, our, fins, proprietary,
Nearest to no: ocogs, any, concerned, there, considerably, shed, always, seminole,
Nearest to that: which, however, what, this, often, where, but, about,
Nearest to into: through, from, dioscorus, lukewarm, around, runners, down, sharpening,
Nearest to new: previous, vlaanderen, rely, actresses, bureaucracies, ponce, sheppard, member,
Nearest to such: these, well, known, licks, many, certain, sedentary, samaritan,
Nearest to of: including, in, include, original, and, for, oration, gunpoint,
Nearest to american: african, british, english, french, european, canadian, trevor, marcuse,
Average loss at step 72000: 3.375021
Average loss at step 74000: 3.349398
Average loss at step 76000: 3.320000
Average loss at step 78000: 3.352304
Average loss at step 80000: 3.377323
Nearest to from: through, into, by, during, between, around, within, affiliation,
Nearest to system: systems, donatello, animating, endowment, shimon, methods, managing, awards,
Nearest to was: is, were, had, became, has, todd, been, be,
Nearest to first: last, second, next, previous, fourth, third, excelled, best,
Nearest to so: too, thus, perilous, then, concluded, if, before, mississippian,
Nearest to it: he, there, she, this, they, still, which, purr,
Nearest to united: rebuilding, philistines, atlas, wikimedia, fraenkel, icbms, savile, tess,
Nearest to there: it, they, he, still, usually, she, we, often,
Nearest to his: her, their, its, my, your, our, the, nouveau,
Nearest to no: ocogs, any, concerned, knotted, occultist, laval, gomez, always,
Nearest to that: which, however, where, this, what, textiles, downplayed, aford,
Nearest to into: through, from, within, over, dioscorus, down, around, using,
Nearest to new: previous, ponce, vlaanderen, pornography, actresses, bureaucracies, acoustical, beverage,
Nearest to such: well, these, licks, certain, sedentary, known, chiuchow, sideband,
Nearest to of: including, in, oration, choreography, platonic, although, definitional, djamena,
Nearest to american: british, french, african, canadian, german, russian, european, english,
Average loss at step 82000: 3.411426
Average loss at step 84000: 3.406127
Average loss at step 86000: 3.391505
Average loss at step 88000: 3.354469
Average loss at step 90000: 3.369536
Nearest to from: through, into, during, towards, by, between, affiliation, tennant,
Nearest to system: systems, mantle, endowment, shimon, donatello, period, evaluations, animating,
Nearest to was: is, had, became, were, has, been, be, todd,
Nearest to first: last, second, next, fourth, best, largest, previous, entire,
Nearest to so: too, thus, before, concluded, perilous, mississippian, analgesic, drafts,
Nearest to it: he, she, there, this, they, numeration, we, often,
Nearest to united: rebuilding, philistines, atlas, wikimedia, veal, fraenkel, tess, uk,
Nearest to there: they, it, he, we, still, now, she, usually,
Nearest to his: her, their, its, your, my, our, the, whose,
Nearest to no: any, ocogs, always, concerned, wildstorm, there, little, only,
Nearest to that: which, however, what, who, where, why, but, unreadable,
Nearest to into: through, from, within, around, back, over, dioscorus, down,
Nearest to new: previous, vlaanderen, wake, different, ponce, pornography, rely, sheppard,
Nearest to such: well, these, certain, known, licks, sedentary, sideband, fes,
Nearest to of: including, for, in, and, include, oration, hobbyists, from,
Nearest to american: british, french, african, german, trevor, canadian, russian, dutch,
Average loss at step 92000: 3.398584
Average loss at step 94000: 3.252340
Average loss at step 96000: 3.357083
Average loss at step 98000: 3.240288
Average loss at step 100000: 3.361009
Nearest to from: through, into, during, in, affiliation, casing, sectarian, meteorites,
Nearest to system: systems, animating, endowment, haley, donatello, evaluations, program, shimon,
Nearest to was: is, became, has, had, were, been, todd, hunts,
Nearest to first: last, second, next, previous, fourth, best, third, same,
Nearest to so: thus, too, then, sometimes, perilous, mississippian, nothing, when,
Nearest to it: he, she, this, there, they, numeration, often, which,
Nearest to united: rebuilding, philistines, atlas, veal, wikimedia, tess, fraenkel, icbms,
Nearest to there: they, it, he, still, now, we, usually, often,
Nearest to his: her, their, my, your, its, our, the, s,
Nearest to no: any, ocogs, only, another, knotted, always, little, odysseus,
Nearest to that: which, however, what, this, who, where, locales, zanzibar,
Nearest to into: through, from, within, in, around, back, predatory, on,
Nearest to new: previous, different, squire, vlaanderen, pornography, sheppard, rely, modern,
Nearest to such: well, known, certain, licks, these, sideband, including, sedentary,
Nearest to of: including, in, original, epa, simplest, oration, stanis, during,
Nearest to american: british, french, canadian, russian, italian, english, trevor, marcuse,
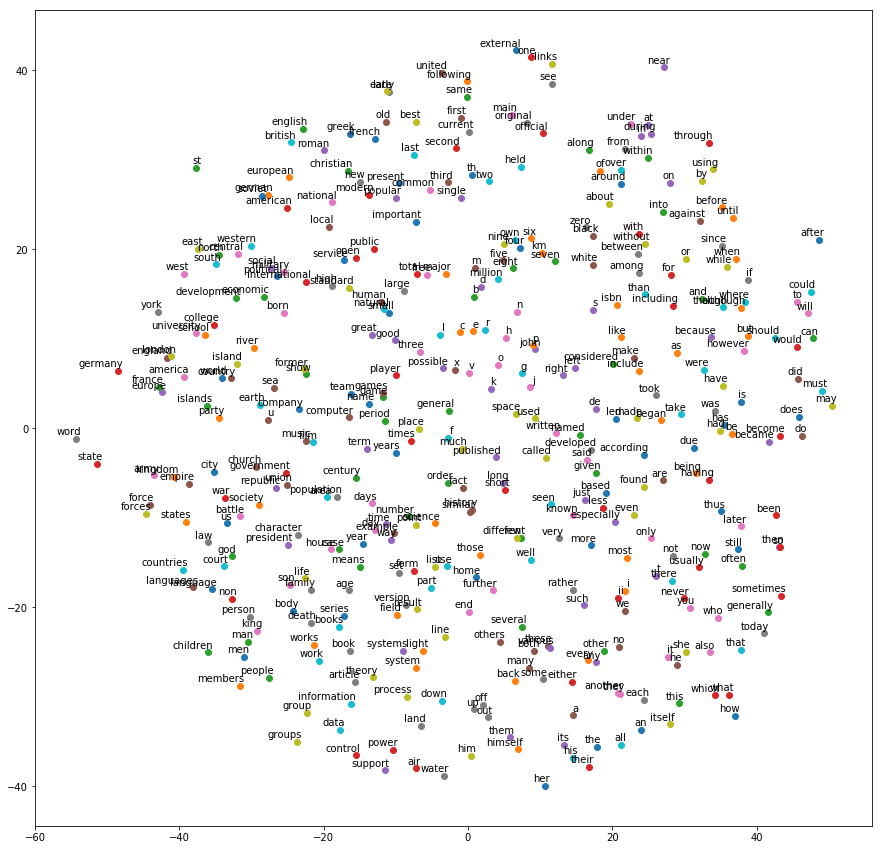
num_points = 400
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
two_d_embeddings = tsne.fit_transform(final_embeddings[1:num_points+1, :])
def plot(embeddings, labels):
assert embeddings.shape[0] >= len(labels), 'More labels than embeddings'
pylab.figure(figsize=(15,15)) # in inches
for i, label in enumerate(labels):
x, y = embeddings[i,:]
pylab.scatter(x, y)
pylab.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points',
ha='right', va='bottom')
pylab.show()
words = [reverse_dictionary[i] for i in range(1, num_points+1)]
plot(two_d_embeddings, words)
Problem
An alternative to skip-gram is another Word2Vec model called CBOW (Continuous Bag of Words). In the CBOW model, instead of predicting a context word from a word vector, you predict a word from the sum of all the word vectors in its context. Implement and evaluate a CBOW model trained on the text8 dataset.
Written on March 4, 2017