
Cifar 10 Demo
Step 1: Organize Imports
from keras.datasets import cifar10
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.optimizers import SGD, Adam, RMSprop
import matplotlib.pyplot as plt
%matplotlib inline
Using TensorFlow backend.
Step 2: Set the constants </br>
CIFAR_10 is a set of 60K images 32x32 pixels on 3 channels
IMG_CHANNELS = 3
IMG_ROWS = 32
IMG_COLS = 32
BATCH_SIZE = 128
NB_EPOCH = 20
NB_CLASSES = 10
VERBOSE = 1
VALIDATION_SPLIT = 0.2
OPTIM = RMSprop()
Step 3: Load dataset
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
X_train shape: (50000, 32, 32, 3)
50000 train samples
10000 test samples
Step 4: Convert to categorical (OHE)
Y_train = np_utils.to_categorical(y_train, NB_CLASSES)
Y_test = np_utils.to_categorical(y_test, NB_CLASSES)
Step 5: Convert to float and normalize
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Step 6: Define the ConvNet model
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(IMG_ROWS, IMG_COLS, IMG_CHANNELS)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(NB_CLASSES))
model.add(Activation('softmax'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 4194816
_________________________________________________________________
activation_2 (Activation) (None, 512) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 5130
_________________________________________________________________
activation_3 (Activation) (None, 10) 0
=================================================================
Total params: 4,200,842
Trainable params: 4,200,842
Non-trainable params: 0
_________________________________________________________________
Step 7: Train the model
model.compile(loss='categorical_crossentropy', optimizer=OPTIM,
metrics=['accuracy'])
history = model.fit(X_train, Y_train, batch_size=BATCH_SIZE,
epochs=NB_EPOCH, validation_split=VALIDATION_SPLIT,
verbose=VERBOSE)
Train on 40000 samples, validate on 10000 samples
Epoch 1/20
40000/40000 [==============================] - 49s - loss: 1.6817 - acc: 0.4007 - val_loss: 1.4203 - val_acc: 0.5048
Epoch 2/20
40000/40000 [==============================] - 50s - loss: 1.3522 - acc: 0.5212 - val_loss: 1.2678 - val_acc: 0.5562
Epoch 3/20
40000/40000 [==============================] - 50s - loss: 1.2236 - acc: 0.5682 - val_loss: 1.1178 - val_acc: 0.6169
Epoch 4/20
40000/40000 [==============================] - 49s - loss: 1.1306 - acc: 0.6026 - val_loss: 1.1047 - val_acc: 0.6215
Epoch 5/20
40000/40000 [==============================] - 50s - loss: 1.0586 - acc: 0.6284 - val_loss: 1.0580 - val_acc: 0.6324
Epoch 6/20
40000/40000 [==============================] - 50s - loss: 0.9928 - acc: 0.6520 - val_loss: 1.0290 - val_acc: 0.6504
Epoch 7/20
40000/40000 [==============================] - 51s - loss: 0.9457 - acc: 0.6695 - val_loss: 1.0483 - val_acc: 0.6361
Epoch 8/20
40000/40000 [==============================] - 50s - loss: 0.8982 - acc: 0.6873 - val_loss: 1.0133 - val_acc: 0.6533
Epoch 9/20
40000/40000 [==============================] - 50s - loss: 0.8508 - acc: 0.7044 - val_loss: 0.9878 - val_acc: 0.6643
Epoch 10/20
40000/40000 [==============================] - 50s - loss: 0.8171 - acc: 0.7158 - val_loss: 0.9993 - val_acc: 0.6665
Epoch 11/20
40000/40000 [==============================] - 50s - loss: 0.7817 - acc: 0.7287 - val_loss: 1.0172 - val_acc: 0.6581
Epoch 12/20
40000/40000 [==============================] - 50s - loss: 0.7443 - acc: 0.7435 - val_loss: 1.0352 - val_acc: 0.6678
Epoch 13/20
40000/40000 [==============================] - 50s - loss: 0.7195 - acc: 0.7515 - val_loss: 0.9955 - val_acc: 0.6712
Epoch 14/20
40000/40000 [==============================] - 50s - loss: 0.6850 - acc: 0.7630 - val_loss: 0.9779 - val_acc: 0.6870
Epoch 15/20
40000/40000 [==============================] - 50s - loss: 0.6564 - acc: 0.7748 - val_loss: 0.9963 - val_acc: 0.6773
Epoch 16/20
40000/40000 [==============================] - 50s - loss: 0.6402 - acc: 0.7800 - val_loss: 1.0141 - val_acc: 0.6766
Epoch 17/20
40000/40000 [==============================] - 50s - loss: 0.6170 - acc: 0.7884 - val_loss: 0.9942 - val_acc: 0.6938
Epoch 18/20
40000/40000 [==============================] - 50s - loss: 0.5967 - acc: 0.7973 - val_loss: 1.0829 - val_acc: 0.6759
Epoch 19/20
40000/40000 [==============================] - 50s - loss: 0.5707 - acc: 0.8053 - val_loss: 1.0302 - val_acc: 0.6851
Epoch 20/20
40000/40000 [==============================] - 49s - loss: 0.5547 - acc: 0.8095 - val_loss: 0.9997 - val_acc: 0.6901
Step 8: Test the model
score = model.evaluate(X_test, Y_test,
batch_size=BATCH_SIZE, verbose=VERBOSE)
print("\nTest score:", score[0])
print('Test accuracy:', score[1])
9984/10000 [============================>.] - ETA: 0s
Test score: 1.00298190823
Test accuracy: 0.6816
Step 9: Save the model
model_json = model.to_json()
open('cifar10_architecture.json', 'w').write(model_json)
model.save_weights('cifar10_weights.h5', overwrite=True)
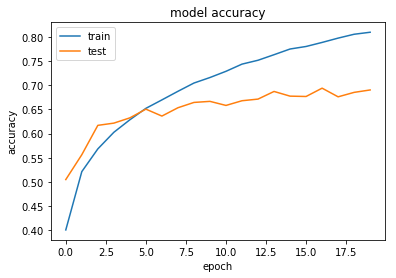
Step 10: Plot the accuracy
print(history.history.keys())
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
dict_keys(['val_loss', 'val_acc', 'acc', 'loss'])
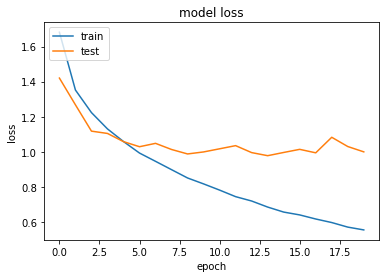
Step 11: Plot loss history
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
-mkc
Written on September 28, 2017